如何开始一场数据分析比赛
说来惭愧,这篇文章是比赛时就开始准备,拖到答辩后才完成。
写这篇文章的缘由是开始做2018科大讯飞AI营销算法大赛, 被好友问到如何入门数据分析,由于我自己算是零基础边比赛边学,一时间不知道如何回答。毕竟“输的时候说什么都是错的”。最后取得第四名的成绩外出答辩受宠若惊,也给了我一点底气聊一聊自己的想法。同时,我必须强调这次比赛多亏了各位大佬的Baseline,否则不可能获得如此成绩。秉承继承分享精神的心情写下一点拙见。
由于我所属的队伍对于特征并无过多交流,以至于最后答辩的时候出现了不知道对方做了什么的尴尬情况。所以这里只能谈谈我自己的一点思路。大多观点借鉴这篇转载文章。
开头的胡言乱语
我一直认为实战是最好的入门材料,数据分析亦如此。所以不要害怕面对比赛一行代码都敲不出来。一般情况下会有 baseline 作为参考,照着 baseline 一行一行敲,查每一个函数的意思、用法,慢慢的学会怎么使用数据分析工具。然后再去考虑研究每一个函数内部的原理。
先让程序跑起来
我们可以借鉴 baseline 中的模型,将所有应该导入的包装好以后以最快的速度跑出一个答案。
数据分析的一般步骤是读数据、填充缺失值、提取特征、模型的训练及预测。但要以最快的速度将模型跑起来就将所有 object 类型的特征 drop 掉。不要考虑提取特征。
我们可以通过 dtypes 查看一个DataFrame 里面的数据类型,通过 isnull 查看 DataFrame 里数据为空的情况。
import os
import pandas as pd
test = pd.read_csv(os.path.join('Data', 'round1_iflyad_test_feature.txt'), sep='\t')
print(test.dtypes)
NAs = test.isnull().sum()
print(NAs[NAs > 0])
运行以后我们可以看到:
instance_id int64
time int64
...(太长省略)
app_paid bool
advert_name object
dtype: object
user_tags 13232
make 4126
...(太长省略)
f_channel 36637
app_id 31
dtype: int64
有这个结果我们就能知道哪些是我们应该删除的特征(比如 advert_name),哪些是我们应该填充的缺失值。现在就可以进行数据预处理:
import os
import pandas as pd
def show_NaN(df):
NAs = df.isnull().sum()
print(NAs[NAs > 0])
def fill_missings(df):
df['make'] = df['make'].fillna('-1')
df['model'] = df['model'].fillna('-1')
df['osv'] = df['osv'].fillna('-1')
df['app_cate_id'] = df['app_cate_id'].fillna(-1)
df['app_id'] = df['app_id'].fillna(-1)
df['click'] = df['click'].fillna(-1)
df['user_tags'] = df['user_tags'].fillna('-1')
df['f_channel'] = df['f_channel'].fillna('-1')
return df
print('Begin to read database...')
train = pd.read_csv(os.path.join('Data','round1_iflyad_train.txt'), sep='\t')
test = pd.read_csv(os.path.join('Data', 'round1_iflyad_test_feature.txt'), sep='\t')
all_data = pd.concat([train, test], sort=False)
print('Begin to do pretreatment...')
all_data = fill_missings(all_data)
numeric_feats = all_data.dtypes[all_data.dtypes == 'object'].index
all_data = all_data.drop(numeric_feats, axis=1)
print('Begin to save database...')
print(all_data.dtypes)
print(all_data.shape)
show_NaN(all_data)
all_data[:train.shape[0]].to_csv(os.path.join('Data', 'train.csv'), index=False)
all_data[train.shape[0]:].to_csv(os.path.join('Data', 'test.csv'), index=False)
PS:我将所有数据文件放入了当前路径的 Data 文件夹中,你可以适应自己的文件路径。
选择模型这方面我也知之甚少,是以后应该重点补足的点。但开始一个比赛模型复制 baseline ,大方向不会错。
import os
import time
import datetime
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
def lgb_train(X_train, X_test, y):
import lightgbm as lgb
from sklearn.cross_validation import StratifiedKFold
X_loc_train = X_train.values
y_loc_train = y.values
X_loc_test = X_test.values
res = X_test.loc[:, ['instance_id']]
model = lgb.LGBMClassifier(
boosting_type='gbdt', num_leaves=48, max_depth=-1, learning_rate=0.05,
n_estimators=2000, max_bin=425, subsample_for_bin=50000, objective='binary',
min_split_gain=0,min_child_weight=5, min_child_samples=10, subsample=0.8,
subsample_freq=1, colsample_bytree=1, reg_alpha=3, reg_lambda=5, seed=1000,
n_jobs=10, silent=True)
# 五折交叉训练,构造五个模型
baseloss = []
for i, (train_index, test_index) in enumerate(list( \
StratifiedKFold(y_loc_train, n_folds=5, shuffle=True, random_state=1024))):
print('---Fold', i)
lgb_model = model.fit(
X_loc_train[train_index], y_loc_train[train_index],
eval_names =['train', 'valid'],
eval_metric='logloss',
eval_set=[
(X_loc_train[train_index], y_loc_train[train_index]),
(X_loc_train[test_index], y_loc_train[test_index])
],
early_stopping_rounds=100
)
baseloss.append(lgb_model.best_score_['valid']['binary_logloss'])
res['prob_%s' % str(i)] = lgb_model.predict_proba(
X_loc_test, num_iteration=lgb_model.best_iteration_)[:, 1]
print('mean:', res['prob_%s' % str(i)].mean())
res['predicted_score'] = res[['prob_' + str(i) for i in range(5)]].mean(axis=1)
print('logloss:', baseloss, np.mean(baseloss))
print('mean:', res['predicted_score'].mean())
now = datetime.datetime.now().strftime('%m-%d-%H-%M')
res[['instance_id', 'predicted_score']].to_csv(
os.path.join('Submit', 'lgb_%s.csv' % now), index=False)
print('Begin to read csv...')
train = pd.read_csv(os.path.join('Data', 'train.csv'))
test = pd.read_csv(os.path.join('Data', 'test.csv'))
all_data = pd.concat([train, test], sort=False)
print('Begin to plot database...')
X_train = all_data[:train.shape[0]].drop(['click'], axis=1)
X_test = all_data[train.shape[0]:].drop(['click'], axis=1)
y = train['click']
print('Begin to train...')
lgb_train(X_train, X_test, y)
至于什么是LightGB、什么是N折交叉训练,以后再去弄明白。这样算是能跑出一个结果了。
提取特征
在有一个能跑通的模型基础上,我肤浅的谈谈特征工程。
首先我们看看每个特征里面有多少类值:
df = pd.read_csv(os.path.join('Data', 'round1_iflyad_train.txt'), sep = '\t')
print(df.nunique().sort_values())
app_paid 1
creative_is_voicead 1
...
nnt 6
creative_height 13
creative_width 20
app_cate_id 22
advert_industry_inner 24
advert_name 34
province 35
advert_id 38
creative_tp_dnf 40
campaign_id 64
f_channel 73
osv 300
city 333
...
instance_id 1001650
dtype: int64
像creative_is_voicead、creative_is_js类别为1的项就可以直接剔除掉;类似于creative_has_deeplink这样的二值特征直接使用问题不会太大;而creative_width这样的特征直接传入也是可以的。
仔细观察就会发现这些特征里面全是ID类离散特征。常理来说,ID类特征是不能直接导入模型的,这样的特征要么One-Hot、要么对其进行排序。我的特征都是围绕这两项展开。One-Hot比较简单而且易于理解,代表着当前类别对Label的影响,这里不过多叙述。
重点说说对ID排序。排序是希望不规则的ID与Label呈线性关系(即ID越大点击率越高之类),那么就这个问题来说广告点击率(CTR)是最为直接的排序方式。首先我们就可以对不同特征的CTR进行一些测验,比如考虑不同类型的广告点击率不同:
import matplotlib.pyplot as plt
df = pd.read_csv(os.path.join('Data', 'round1_iflyad_train.txt'), sep = '\t')
res = df.groupby(['creative_type'])['click'].mean().reset_index(name='creative_type_ctr')
print(res)
x, y = 'creative_type', 'creative_type_ctr'
data = pd.concat([res[x], res[y]], axis=1)
data.plot.scatter(x=x, y=y, ylim=(0, 1))
plt.show()
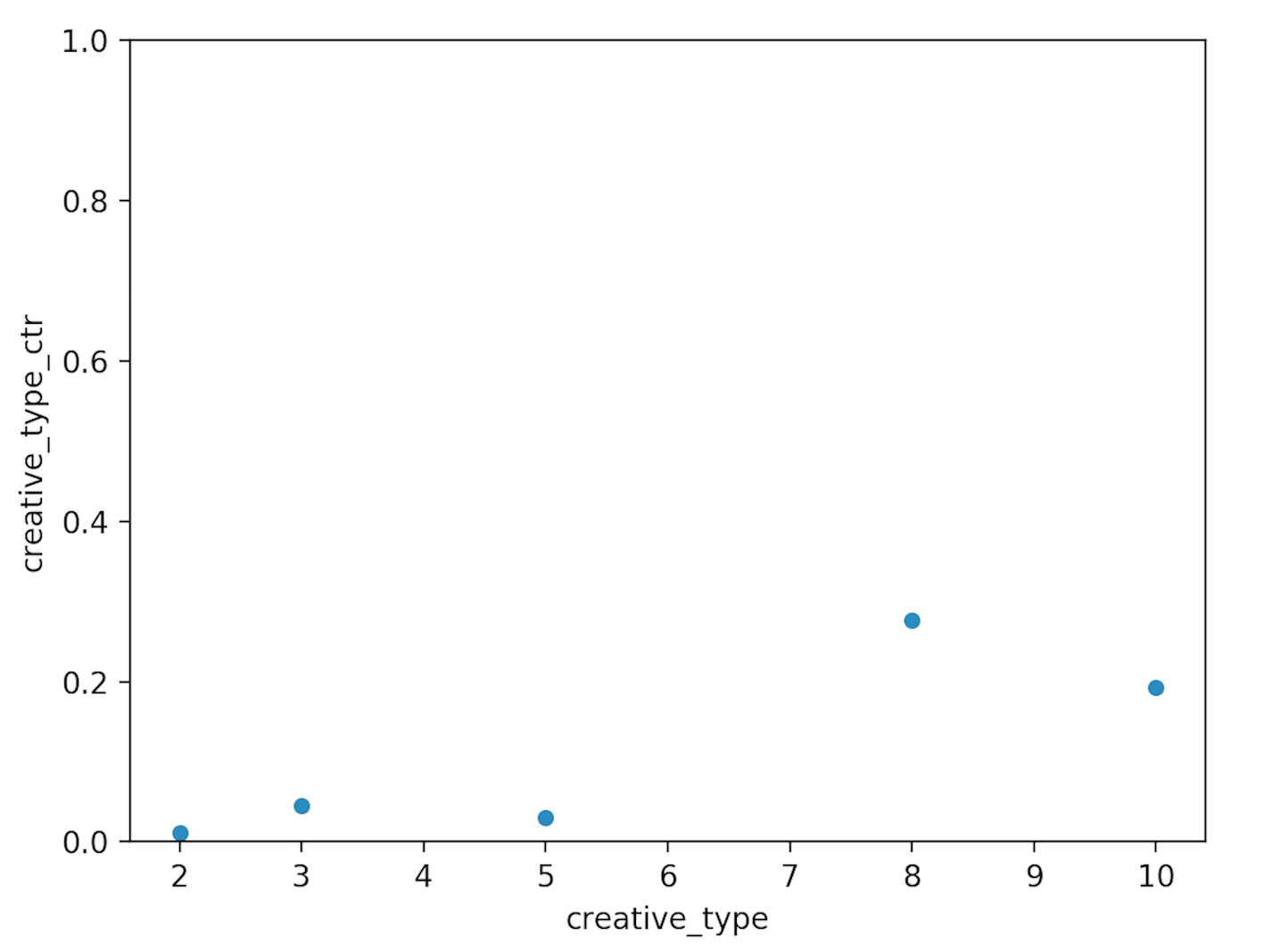
我们可以看到编号为类型2、3、5的广告点击率明显不如类型8、10的广告。那么我们可以这样写:
df = df.replace({
"creative_type" : {2 : 1, 5 : 2, 3 : 3, 10 : 4, 8 : 5},
})
这样广告类型和Label就正相关了。我们还可以猜测用户的网络状态(nnt)也与点击广告有关等等。
像这样简单的给ID排序会有一定的效果,但是可能仍不尽理想。因为不同的人会喜欢不同的广告类型,比如化妆品类广告可能点击率很高,但是如果推送给不化妆的人点击率会大大降低。也就是说同一类型的广告对不同的人来说点击率是不同的:
df = pd.read_csv(os.path.join('Data', 'round1_iflyad_train.txt'), sep = '\t')
df['creative_type_nnt'] = df['creative_type'].astype('str').str.cat(
df['nnt'].astype('str'), sep='_')
df['creative_type_nnt'] = df['creative_type_nnt'].map(dict(
zip(df['creative_type_nnt'].unique(), range(0, df['creative_type_nnt'].nunique()))
)).astype('int32')
res = df.groupby(['creative_type_nnt'])['click'].mean().reset_index(
name='creative_type_nnt_ctr')
print(res)
x, y = 'creative_type_nnt', 'creative_type_nnt_ctr'
data = pd.concat([res[x], res[y]], axis=1)
data.plot.scatter(x=x, y=y, ylim=(0, 1))
plt.show()
那么将creative_type和nnt拼接起来并重新编号ID(利于输出),得到下图:
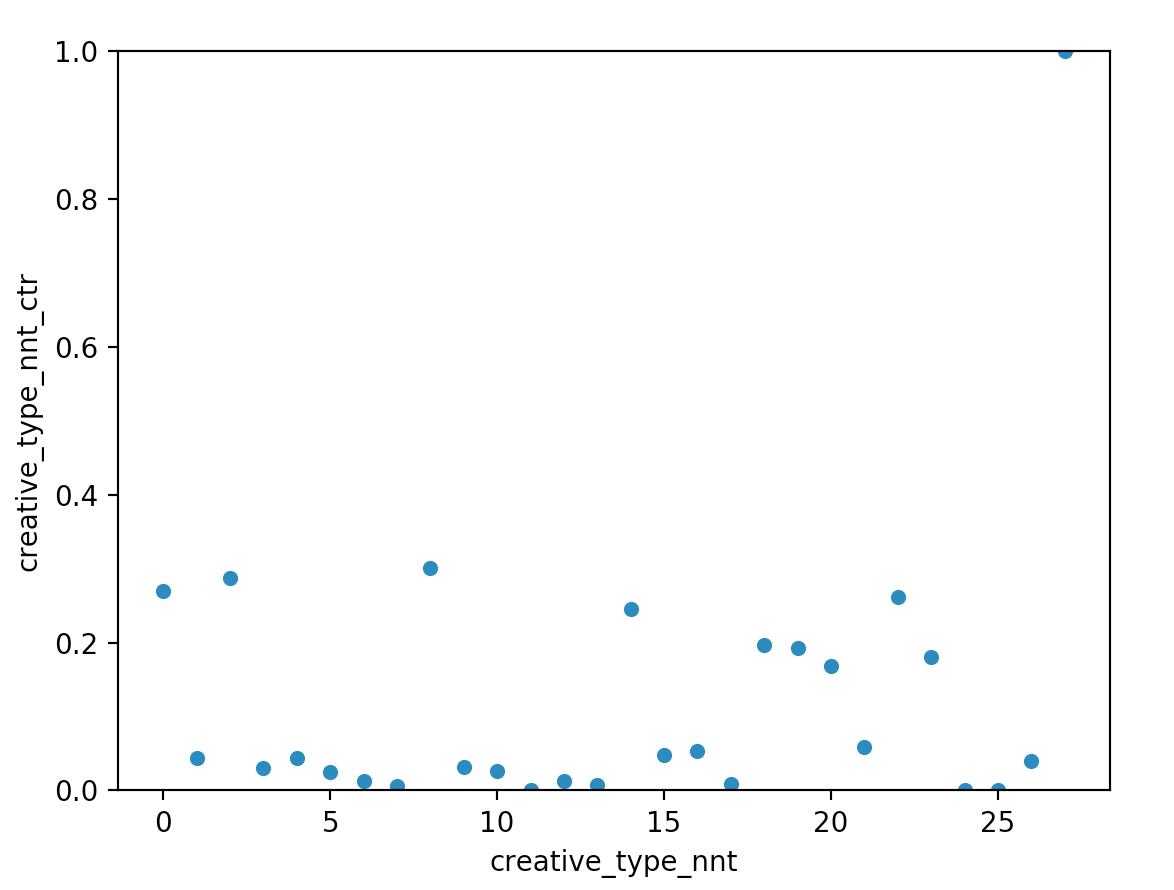
我们可以看到相比于之前的creative_type,现在每个ID的区分度更大,但是好像开始无法分辨creative_type之间的关系了。这是因为一维只能描述一种排序关系,要想实现特征拼接而尽量不丢失原始信息就应该使用One-Hot转化为多维来表示不同的creative_type,类似于下面实现:
df = pd.read_csv(os.path.join('Data', 'round1_iflyad_train.txt'), sep = '\t')
res = df.groupby(['creative_type', 'nnt'])['click'].mean().reset_index(
name='creative_type_nnt_ctr')
print(res)
x, y = 'nnt', 'creative_type_nnt_ctr'
data = pd.concat([res[x], res[y]], axis=1)
data.plot.scatter(x=x, y=y, ylim=(0, 1))
plt.show()
通过下图就可以看出在creative_type相同时,nnt不同CTR不同。这就可以表示不同nnt在同一creative_type下的偏好:
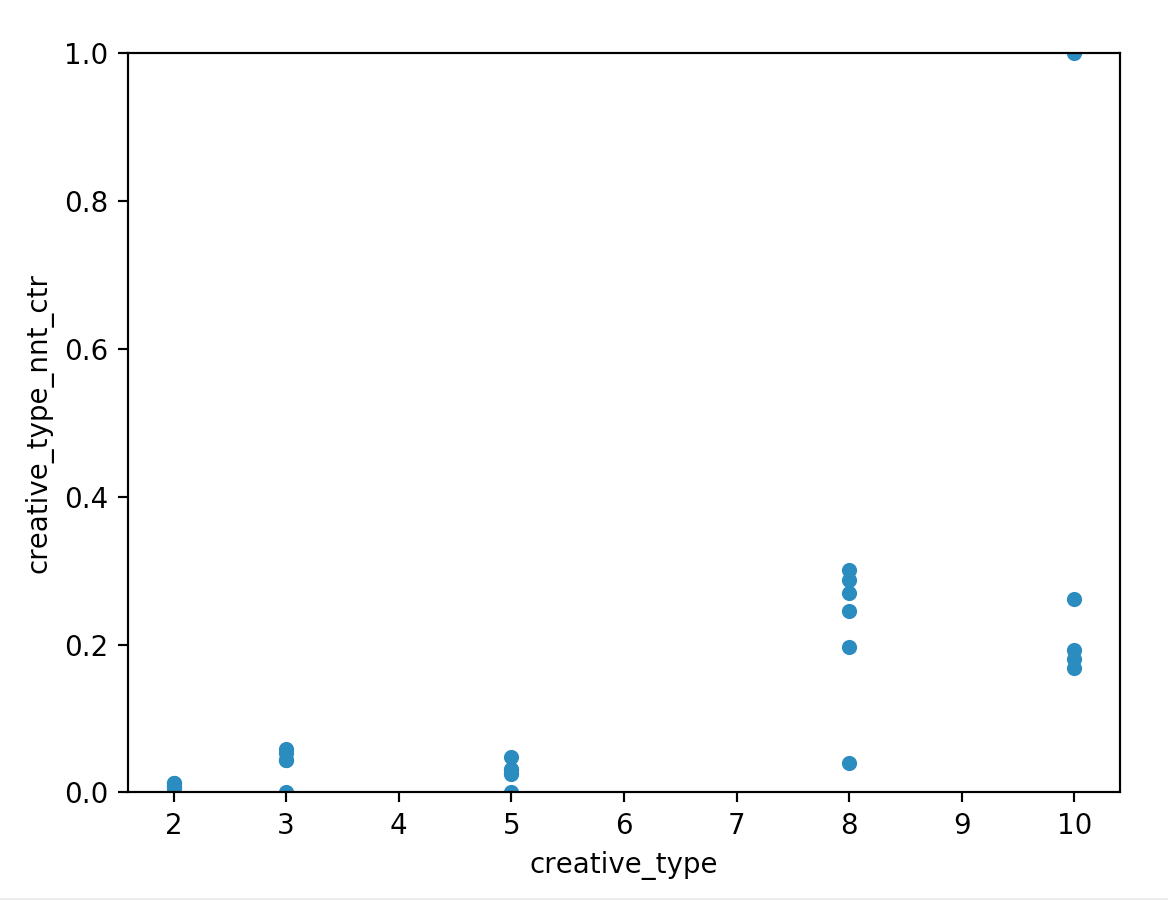
通过上图又出现了一个问题,就是在creative_type为10的时候有一个点的ctr值为1。我们查看这个点的实际信息可以看到:
creative_type nnt ctr count
10 2 1.000000 1
creative_type=10 & nnt=2情况的点击率为1,但是只发生了1次。很明显这个点击率不可信,这时就要用到平滑处理,去尝试预测真实的点击率。
在一行数据在某一特征下出现次数可能很少(比如model),但是在另一些特征下出现次数会相对较多(如nnt)。我们说出现次数少的特征可信度低,出现次数多的特征可信度高。用可信度高的特征去预测可信度低的特征的点击率也许可行:
def get_ctr_matrix(data, src, dest):
temp = data.loc[data['label'] != -1, [src, dest, 'label']]
src_gb = temp.groupby([src])
src_frame = src_gb.agg({'label': 'sum'}).rename(
columns={'label': 'src_sum'}).join(
src_gb.agg({'label': 'count'}).rename(
columns={'label': 'src_count'})).reset_index()
del src_gb
dest_gb = temp.groupby([src, dest])
dest_frame = dest_gb.agg({'label': 'sum'}).rename(
columns={'label': 'dest_sum'}).join(
dest_gb.agg({'label': 'count'}).rename(
columns={'label': 'dest_count'})).reset_index()
del dest_gb
frame = pd.merge(src_frame, dest_frame, on=[src], how='right')
del temp, src_frame, dest_frame
frame['rate'] = (frame['src_sum'] + frame['dest_sum']) / (frame['src_count'] + frame['dest_count'])
frame.drop(['src_sum', 'src_count', 'dest_sum', 'dest_count'], axis=1, inplace=True)
data = pd.merge(data, frame, on=[src, dest], how='left').fillna(0)
del frame
src_hot = pd.get_dummies(data[src], dtype='float32')
for h in src_hot.columns:
src_hot[h] *= data['rate']
data.drop(['rate'], axis=1, inplace=True)
return sparse.csr_matrix(src_hot[data['label'] != -1], dtype='float32'), sparse.csr_matrix(src_hot[data['label'] == -1], dtype='float32')
ctr_list = [
('creative_width', 'app_id'),
('nnt', 'creative_id'),
]
ctr_train_csr = sparse.csr_matrix((len(train_x), 0))
ctr_predict_csr = sparse.csr_matrix((len(predict), 0))
for (src, dest) in ctr_list:
ctr_t, ctr_p = get_ctr_matrix(data, src, dest)
ctr_train_csr = sparse.hstack((ctr_train_csr, ctr_t), 'csr', 'float32')
ctr_predict_csr = sparse.hstack((ctr_predict_csr, ctr_p), 'csr', 'float32')
print(src, dest, 'over')
print('ctr feature prepared !')
PS:本来由于维数过大,笔记本8G内存不够用,差点在这里弃赛。后来林有夕开源救我一命,用到了CSR。
在此之后出现了一个新的问题:若一个可信度高的类别转化率与可信度低的猜测转化率是相同的,可重要性应该不一样。当前特征没有体现这个区别。最后通过加入每个类别数量在全集中的占比来反映一个广告推送的置信度。解决了同一转化率下,不同类别可信度不同的问题。
最后,也是我没有完成的问题:如何解决针对用户点击率计算的多样化。当前投放特征主要集中在广告方和APP方,计算不同类人的偏好应该能优化这种情况。
思考与总结
- 无论是比赛过程中还是比赛结束后,深切体会到自己理论知识的缺乏。
- 离散特征做连续化是主要思路。
- 缺失值可以填充mean,填充新类别,也可以用其他特征预测。
- Baseline有时候是个好东西,有时候会被骗。
- 肝真的能弥补一些东西,但不是全部。